


AMD and the AI Race: a User's Perspective
Is AMD finally a serious a contender in the competition for AI compute?

Introduction
If you told me a year ago that I’d be doing all of my deep learning research and tinkering on AMD GPUs, I would’ve laughed at you: did you read around? Everyone agrees: ROCm is buggy, unpolished, and just not worth the hassle. Only NVIDIA matters. AMD doesn’t care about AI, they’re just making a token effort to make it look like they’re doing something.
But ever since this year started, I’ve taken a detour, started by a friend of mine who let me use his AMD Radeon 7900 XTX for training models: at the time, I wasn’t exactly thrilled about leaving the sweet, sweet and safe comfort zone of CUDA and CuDNN, but ready to give it a try regardless.
But contrary to what I had read, what I found wasn’t a broken, buggy mess. It was, dare I say — usable, even promising!
Advanced Micro Devices and GPU Compute: A complicated history
But before we properly dive in, let’s look at some history, at least from my perspective.
Long before I even knew deep learning was a thing, young me (was I ten or twelve? don’t remember) was interested in 3D rendering, not the game type mind you, but doing things in Blender. Back when Cycles was first introduced, I was watching a video by my then-favorite Blender Youtuber.
Cycles is a render engine that uses path tracing for its lighting and reflections: beautiful and accurate, but slow. I watched in amazement as he switched from CPU to GPU compute and it just—sped up, like magic, “the GPU is a lot faster than the CPU”, he said.
Excitedly, I downloaded that version of Blender with Cycles, only to be devastated by the fact that GPU compute was CUDA only, and wasn’t even an option on my ATI Radeon card.
But ZD, what does this have to do with ROCm? It means AMD has always been behind when using the GPU for non-game graphics tasks, and I’ve been conditioned to see them as a disappointment in that area — hence my lack of initial faith in this.
ROCm today: Holy Shit, it Just Works?
Fast forward to today. After a whole teenage plus a bit of adult life seeing AMD as barely competitive in anything GPU compute-related with the exception of crypto, I didn’t expect much from their AI stack: ROCm, MiOpen, HIP, et al. Maybe I’d get to train a model after debugging 10 bugs if I were lucky. Reddit was full of people complaining about AMD and telling people to just pay for NVIDIA hardware if they wanted to do any serious AI work.
But they’re wrong.
I mean, yeah, there are a few special considerations here and there — I strongly recommend sticking to the official Docker containers, as the ROCm environment is more delicate than the CUDA one, but when you do things right, everything works well out of the box!
You can import torch. You can train transformers, diffusion models, GANs, convnets and more— right now on AMD GPUs. You can load whatever model you desire from HuggingFace and run it too: tensor (AMD calls the matrix) cores go brrr— yes, they actually get used!— when appropriate. It just works!
In my case, I started out with said friend’s 7900 XTX with ROCm 6.3, then graduated to an Instinct MI300X with the then-recently released ROCm 6.4, thanks to Hot Aisle. That update was quite important software-wise too: 6.4 brought FlexAttention, other latest PyTorch goodies, and felt smoother in general.
It made me realize: AMD isn’t just doing a token effort like I previously believed: they’re serious about this, they want to catch up.
AMD’s Immediate Challenge: Software, Software and Community
AMD’s line-up of datacenter GPUs is very formidable when you glance at the specs — let’s check out the Instinct MI300X

This fine piece of engineering has 192 GB of HBM3 VRAM (2.4x more than the H100’s 80GB) and delivers 1307.4 TFLOPS of peak theoretical BF16 performance (without sparsity). On the hardware front alone, AMD is very well positioned against NVIDIA.
But machine learning is far from hardware alone: you need a language to speak to the GPU with — HIP is AMD’s equivalent to CUDA, math libraries like green team’s cuBLAS, cuDNN, CUTLASS for deep learning calculations; AMD’s analogs like rocBLAS and MIOpen do the job well enough, PyTorch bindings, debugging tools, you get the point.
AMD has made great strides in catching up to NVIDIA in this department: ROCm has gone from a mess (as evidenced by people complaining about it the past few years) to actually usable. However, not only does the software have to exist and work well, but you also need ecosystem and community: a bunch of people who know how to run it and can help others. This is where NVIDIA will remain ahead for a while: they’ve been the de-facto ecosystem for machine learning since forever, and 99% of people in this field are familiar with it.
This is a bit of a problem for AMD, because whenever someone makes an optimized kernel for some operation — like FlashAttention — and releases it, chances are they’ll write it in CUDA, and won’t bother with a Composable Kernel, instead relying on someone else to contribute it. Yes, ROCm has HIPIFY for CUDA → HIP, but it’s complicated to set up and use, and might not even work: I couldn’t use the S4 CUDA kernel because it depended on CUTLASS, which has no AMD equivalent.
Thankfully, OpenAI Triton is slowly displacing CUDA as the de-facto GPU kernel programming language — owing to its ease of use —, which AMD smartly has first-class support for: every Triton kernel I tried worked out of the box without adjustments.
The Developer is the battlefield: AMD’s Fight for Mindshare
Now, what I said about community? They know this. AMD isn’t merely sitting back, selling GPUs, and hoping ROCm will quietly catch up: they’re well aware that their GPUs are good and the software is formidable, now they just need you to care.
GPU SWE Anush Elangovan, affectionately dubbed ‘King Anush’ by SemiAnalysis, is actively scouring Xitter at all times for AMD/ROCm related tweets/issues and getting involved. AI at AMD is helping clouds give out free GPU time, like the MI300X I’ve got access to and have been able to do cool stuff with thanks to Hot Aisle.
AMD engineers are monitoring and solving issues with ROCm, contributing HIP kernels to popular operations, they even have their small in-house research department actively contributing models trained on their hardware like Instella, showcasing that yes, you can do serious stuff on AMD hardware.
And at AMD Advancing AI 2025, they’ve announced the AMD Developer Cloud, allowing anyone with a credit card to spin up an MI300X instance with the AI toolkit of their choice already installed, with SSH and JupyterLab — and are offering $50 worth of credits, 25 free MI300X hours, to anyone who applies and gets it approved (I did). When I first heard of the AMD Instinct lineup, I dismissed it because I couldn’t find anywhere to rent any. Now that problem’s solved.
Much like their software endeavors, AMD’s community outreach shows their determination to become a real force in AI compute.
Advancing AI 2025: AMD’s Pitch to the World

This June, I’ve come to witness (tho not in person) AMD’s Advancing AI 2025: where they announced their line-up of GPUs, the Developer Cloud, and a bunch more goodies. But I want to focus on the partnerships:
Meta’s AI team discussed deploying MI300X at scale for Llama 3 and 4 inference and expressed support for MI350 and future MI400 plans
OpenAI’s CEO Sam Altman spoke about their close collaboration with AMD – revealing that OpenAI’s research and even GPT-4 model training runs on Azure instances powered by AMD MI300X GPUs in production
Microsoft and Cohere similarly shared that they are running large models on MI300X in cloud and enterprise settings
Do you see what’s going on here? Top-tier AI labs and cloud providers are publicly aligning with AMD, something that would have seemed impossible just a few years prior, back in the days of V100s and A100s
Having such big boys visibly showing trust in AMD’s products means that they are a serious player.
But not all is sunshine and rainbows. For example, AMD is starting to copy NVIDIA's tendency for chart crimes.
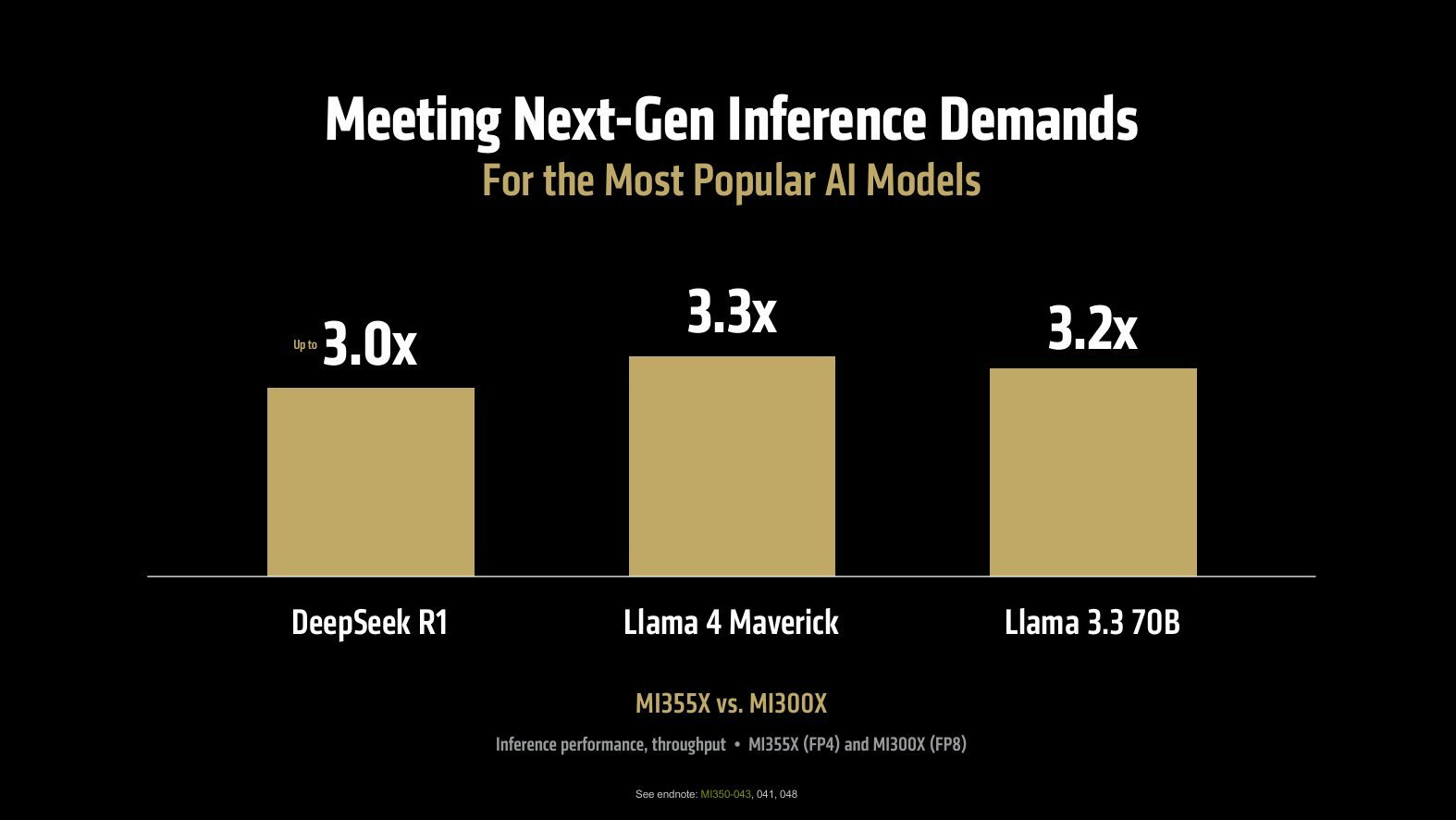
In their LLM inference example, they’re comparing their next-gen MI355X on FP4 vs current MI300X on FP8: that is, half the precision for the newer GPU. At that point, it’s basically trivial to showcase a big, fancy performance gap.


But this is bad! FP4 is less bits than FP8: performance will degrade. It’s not a true apples-to-apples comparison. Bad AMD, bad!
In fairness, you could argue that NVIDIA is partially to blame as they love (and started with) doing this kind of chart crimes, and AMD is kind of forced to in return because their figures would look unimpressive otherwise.
Too safe? Why I think AMD should be Bolder
Remember AMD’s developer cloud that I mentioned earlier? Well, it’s not an original idea: Google did it first, it was called the Tensorflow Research Cloud, now TPU Research Cloud, where they have (and continue to) give out TPU time to anyone who asks, with few questions, and the only requirements being that you don’t do bad stuff with it, open source your research, and write about your experience. They give it out like candy, it’s pretty nice.
In fact, my first experience with LLMs (before they were even called LLMs, we just called them GPTs) was finetuning GPT-J-6B on a dataset of pony fanfiction back in 2021, all with TPUs from the TRC. GPT-J itself was pretrained on TPUs as well: the default quota you get is already very good (enough to comfortably finetune the aforementioned model), but you can ask for more: EleutherAI back then got a TPU v3-256 pod for approximately 5 weeks.
According to Grok, in modern terms, that’s equivalent to 107.5k H100 hours — and that’s in 2021, when the most performant GPU was the A100 and the H100 was probably still in the blueprint stage.
And Google just gave away said caliber of compute to EleutherAI, through their research cloud.
Let me dig into my emails. This is the quota I was given at the moment, just for asking.


Once again according to Grok, the on-demand quota I got would be equivalent to 20 H100s, for a whole month with easy extension. Now let’s compare it to AMD’s current offer:

With AMD’s developer cloud, I got $50 worth of credits, which at $2/GPU/hr for MI300X would be just 25 MI300X hours. Now I’m not one to bitch about free things, free things are good — and I know AMD isn’t Google, they don’t have the same resources, but I think this is them just playing it too safe. As a SemiAnalysis article noted, AMD needs their own GPT-J moment, and the amount of compute they give out is only enough for toying around for a little, but not anything serious.
And I argue, naming your thing Developer Cloud is going to draw comparisons with other things named Developer Cloud like it. So, I think it’s a fair comparison.
This brings me into my second point: AMD’s in-house research group is playing it too safe: they’re just releasing LLMs and VLMs like the aforementioned Instella. Now, this is not a diss against the engineers themselves: if you read the technical report, you can see that real innovation and engineering prowess went into these creations, but rather my point is that there are a trillion of these models out and about. You need to be a DeepSeek to stand out; otherwise, it’s all going to be lost into the sea of models.
There’s nothing exciting about these models in principle, which means they aren’t going to get popular on their own. AMD’s AI division should make something that can become popular on its own merit, maybe in a field like audio or image: but that requires real risk-taking: the kind where there’s a real chance you might just not succeed. LLMs are safe, but boring.
But the world rewards (albeit good) risk-takers.
Conclusion
There’s a lot more that I could’ve written and gone into detail, but I want to end it here. Unlike my other technical writings, this is more of a high-level, human overview of the landscape of things.
Using AMD GPUs for deep learning is a thing that seemed impossible to me just a year or two prior. But now I am doing it.
If AMD keeps up the momentum, then, for the first time, I can say that NVIDIA now has real competition in this field. But AMD will not have a singular Ryzen moment over NVIDIA like it did against Intel; it’s going to be a slow battle.
And this is good. I don’t want the whole AI market to be dominated by a single vendor (and Google).