
On Activation Functions in Transformers

Background
The original Attention is all You Need paper proposed the Transformer — which combines multi-head attention and the feed-forward layers.
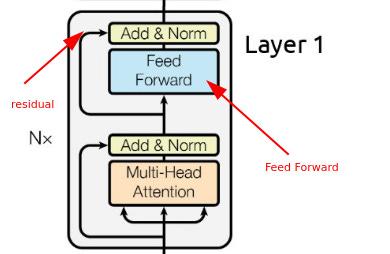
The attention layers tell the model what to focus on, and the feed forwards help the model “think” or digest the information.
In the feed forward layers, there is usually a linear transformation projecting the input into a higher dimensional space (usually 2x or 4x), followed by an activation function, then another transformation back into the original channel size.
As originally proposed, the activation function is a ReLU, which merely caps all values to a minimum of 0 (or in simpler words, doesn’t let anything negative go through).
GLU Variants
However, in 2020 a very popular paper proposed several GLU variants, with the most popular today becoming SwiGLUFFN
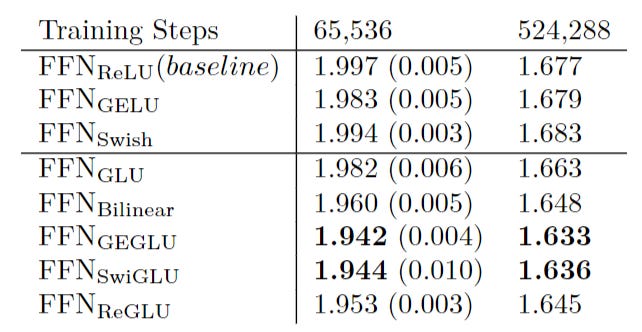
While certainly effective, one weakness of most GLU variants is that they introduce more parameters due to the additional forward expansion and gating. Let’s look at DINOV2’s implementation
class SwiGLUFFN(nn.Module):
def __init__(
self,
in_features: int,
hidden_features: Optional[int] = None,
out_features: Optional[int] = None,
act_layer: Callable[..., nn.Module] = None,
drop: float = 0.0,
bias: bool = True,
) -> None:
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.w12 = nn.Linear(in_features, 2 * hidden_features, bias=bias)
self.w3 = nn.Linear(hidden_features, out_features, bias=bias)
def forward(self, x: Tensor) -> Tensor:
x12 = self.w12(x)
x1, x2 = x12.chunk(2, dim=-1)
hidden = F.silu(x1) * x2
return self.w3(hidden)The gating requires that the forward expansion be 2x bigger than normal for the next chunking. If you’ve got a crap ton of compute and are only using linear layers, this is fine.
The Primer architecture proposed ReLU squared, which is as simple as it sounds. From my experiments, it does perform better than normal ReLU, but not as well as SwiGLU.
The Problem and Solution
I’m currently working on speech synthesis, and my decoder (technically another encoder), since it works with mel spectrograms, has convolutional instead of fully connected layers in its feed forward layers, which are more expensive, it works with pretty large sequence lengths (200 - 1100), and I don’t have a shit ton of compute, I’m not drowning in VC money (sadly).
Ideally, I wanted something better than ReLU2, but not as computationally expensive as the GLU variants.
I looked at GELU:

But I want something faster, so I looked elsewhere. I found this function called Alpha Plus Tanh Times (APTx), which has a similar curve but is 2x faster than Mish (which is itself marketed as faster than GELU).
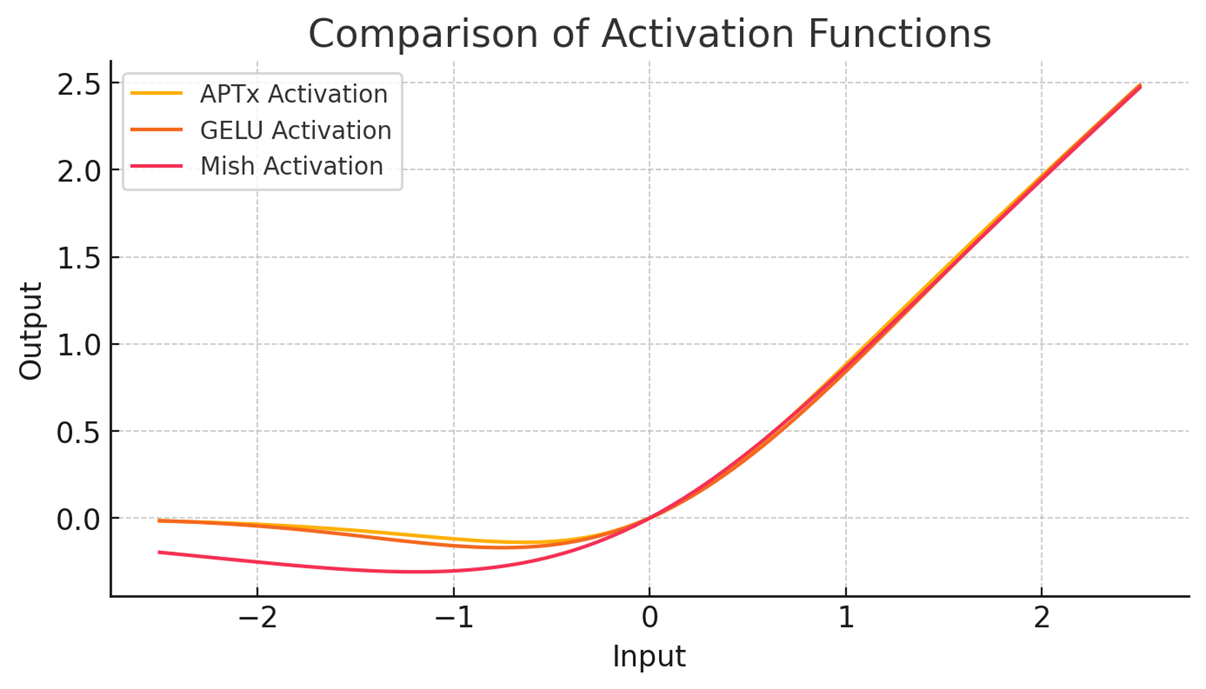
Where alpha, beta are 1 and gamma is 0.5. I had also tried DPReLU, so inspired by that, I set up a basic transformer to classify IMDB on a Jupyter notebook and experimented, finding that making the beta and gamma trainable parameters increased performance. Then, inspired by ReLU2, I squared the output:
This function managed to consistently score the highest eval and test accuracies on my toy classification runs, and only adds a little bit of complexity. After that, I brought it into the decoder, and it scored significantly better than ReLU2, just like the toy run.
To my knowledge, there’s no real study on parametric activation functions in Transformers. My theory is that the gradient is able to adjust the shape for maximum optimization and thus this increases performance.
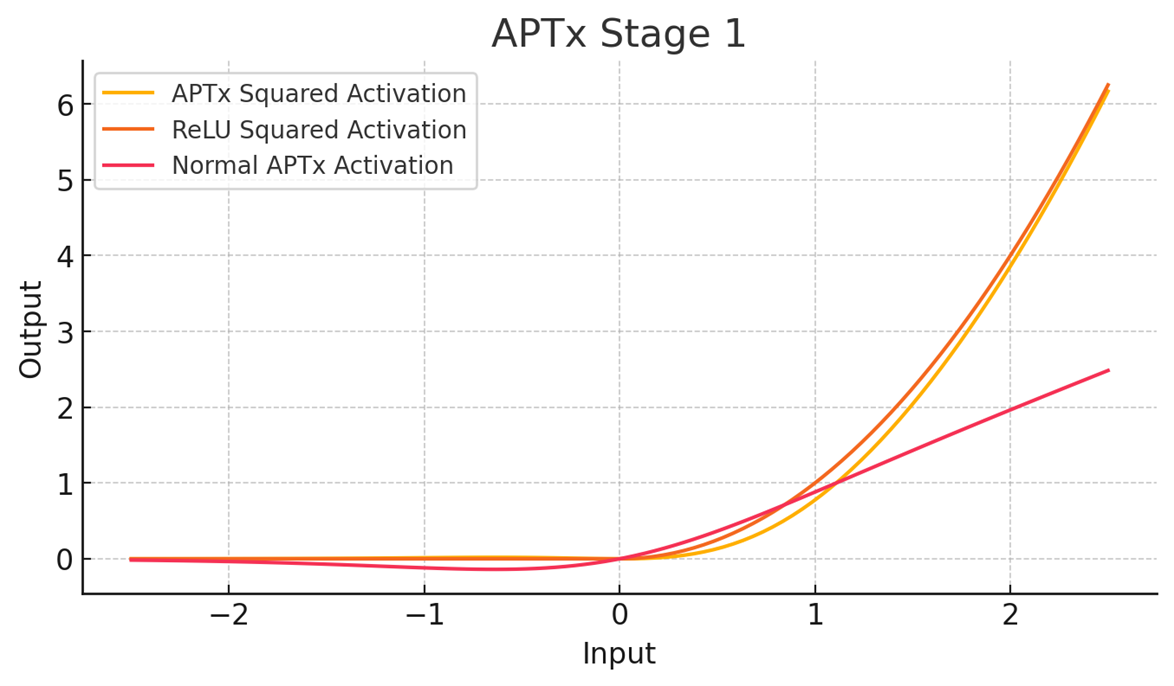
To confirm my theory, I took a trained model and plotted the activations to see if I could spot anything of interest.
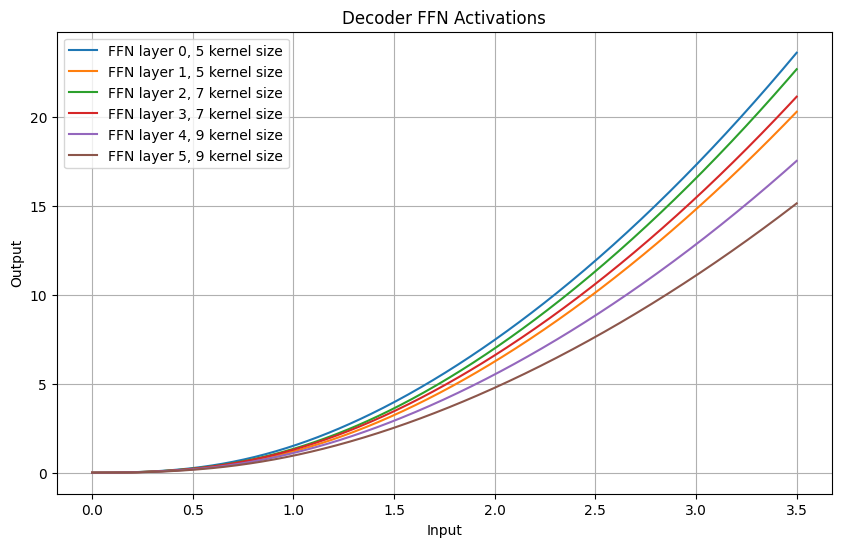
As we can see, there is a pattern! There seems to be some clustering or something going on.
So yeah, now I roll with APTx Squared — or, as I now call it, APTx Stage 1. It’s trainable and only a bit more costly than ReLU2, while having much better performance.
I have no popular benchmark results, as those are expensive. Who do you think I am, Google DeepMind? You’ll just have to trust me bro — or try it yourself! Code’s at the very bottom of this post.
ReLU GT
Looking at the characteristics of it, I decided to piece together another activation function, this one based on ReLU. I present to you, ReLU GT:
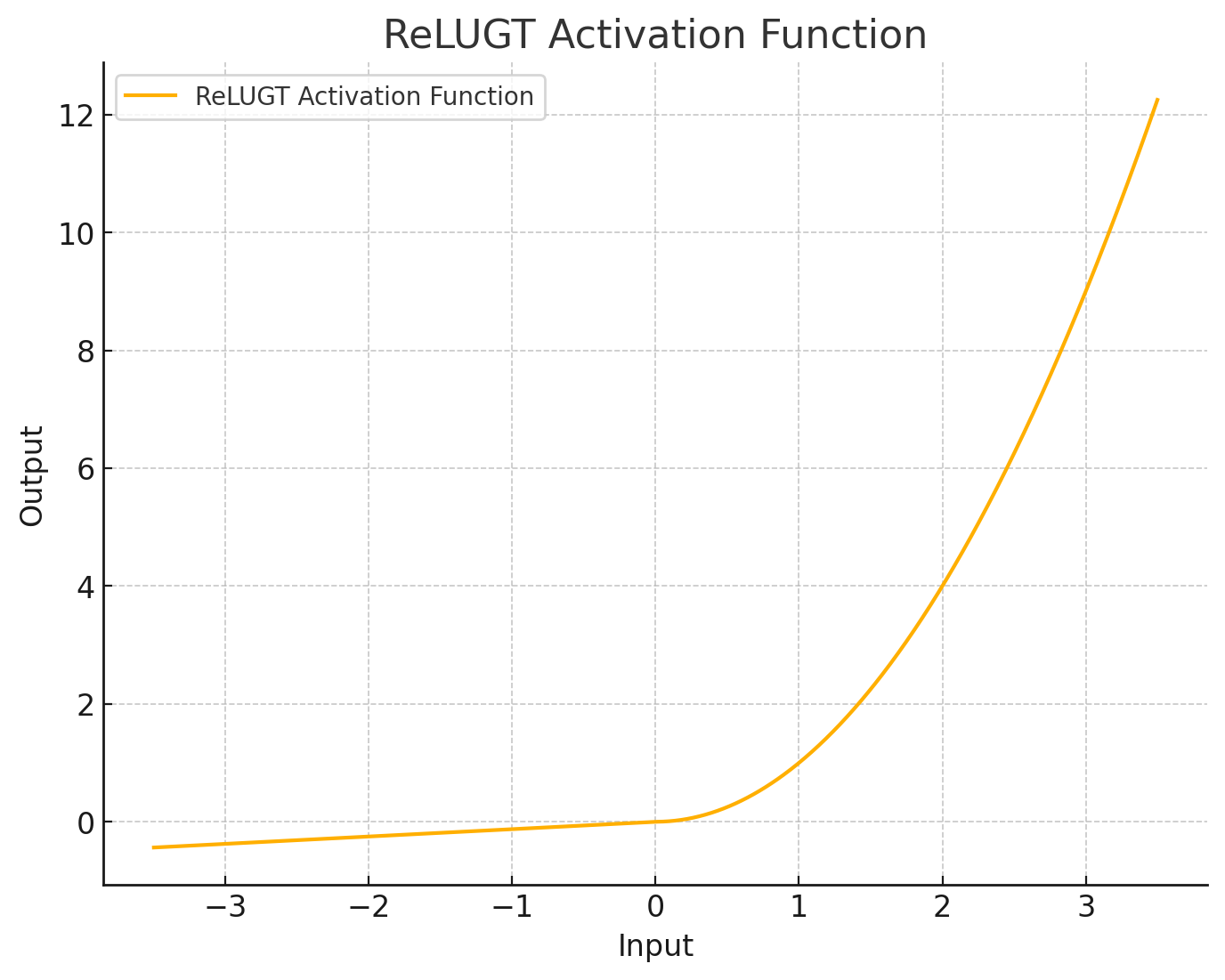
It has a trainable negative slope (initialized to 0.05), a static negative alpha (2.5), and a trainable positive alpha (1.0), squaring the positive part. I have no mathematical justification for this function, I just built it based on what I noticed that the gradient likes.
In my classification test it was practically equal to the earlier APTx squared, except that it gained val accuracy faster but was slightly lower on the test one (although that is probably attributable to the stochastic nature of training). I haven’t tested it in any “real” models, though.
Conclusion
There is definitely potential in trainable activation functions. Notably, the KAN vs MLP paper noted that a big advantage of KANs is specifically their parametric activation function, and that when they did the same with MLPs, their performance also improved.
I hope this post makes more people think beyond WhateverGLU as the default activation function for FFNs.