
Wave U-Net Enhancer
How to morph a U-Net into a synthesis-first audio enhancement model

Introduction

The U-Net, originally made for medical image segmentation, has found a wide variety of uses, thanks to its powerful and flexible design. Among those has been an adaptation for audio, the Wave U-Net, which works on audio frames directly rather than relying on time-frequency representations. By operating in the time domain, the Wave U-Net preserves precise temporal structure while still benefiting from the multi-scale context provided by its encoder-decoder hierarchy and skip connections.
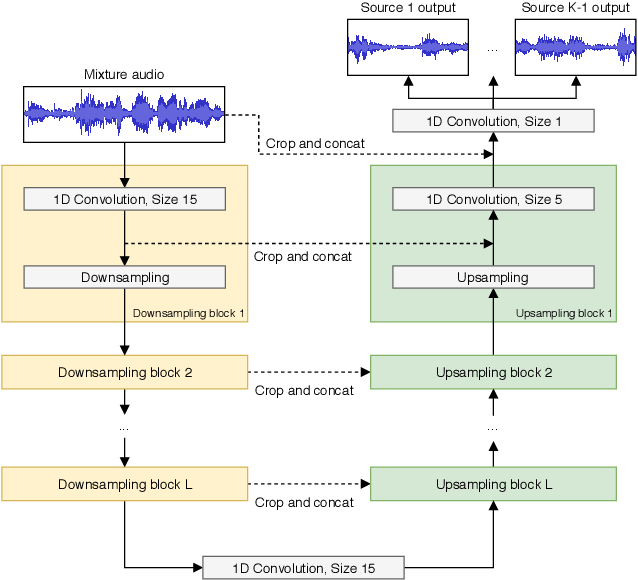
The Wave U-Net was used to great effect in music stem separation, audio bandwidth extension, et al. This is in large part because of the downsampling, which aggressively extends the receptive field and allows the network to operate at multiple temporal resolutions, and skip connections, which give the decoder access to information normally lost in downsampling.
The Experiment
My task here is speech bandwidth extension + repair. I’ve got paired data: audio after going through a neural speech codec (NeuCodec) in 24KHz, and the original in 48KHz. This audio is degraded because of compression loss and being a bit out of distribution for the codec, and this network’s objective is both to upsample from 24 to 48KHz, and repair codec artifacts.
So, I had an AI agent write me a dataloader that provides audio pairs, plugged the original Wave U-Net in, the GAN setup from HiFi-GAN, and ran it.
…
No matter what I tried, the model refused to learn well. The output audio sounded a bit better than the input, but only a tiny bit, and the artifacts persisted. I tried adjusting:
Perceptual losses
GAN losses (hinge vs LSGAN, weights)
Channel sizes and layer counts
Normalization
So, what’s going on? I’ve seen what the Wave U-Net can do, it can split music into stems with just waveform losses, so what’s going on?
Skip Connections
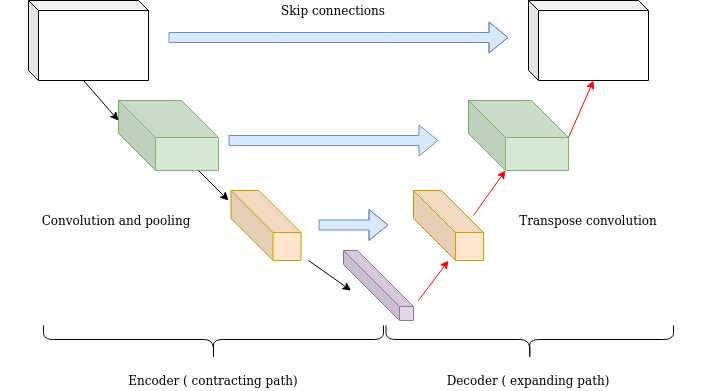
Let’s zoom in for a little on these. As I’ve said before, skip connections serve as an information highway between the encoder and decoder. Why? Because the U-Net is built with this big assumption: stuff from the input, at every level, is useful for the output. For stem separation (the Wave U-Net’s original purpose), this makes sense: the drums, bass, vocals, et al. are all in the input, and the objective is just to isolate each.
But my input audio is low-quality and degraded. The skip connections were letting the model “cheat” by just copying what it was fed, and with so much information easily available, never got pressure to actually improve. In other words, my tasks breaks the assumption of the skip connection: stuff from the input is actively harmful for the output. We want the model to synthesize, not extract, nor refine.
This all clicked as I was reading papers and stumbled upon DEMUCS. In there, they:
Switched the skip connection from concatenative to residual
Replaced upsample-conv with transposed convolution
Added a gated linear unit to each layer
Upped the stride from 2x to 4x
Replaced the bottleneck with an LSTM
All of these made the U-Net more generative. But DEMUCS was still for stem separation: a task you could describe as segmentation in the audio domain.
Therefore, to force the model to actually generate, I had to remove almost all skip connections, except for the last and penultimate layers, which, in a 6-layer model with 4x downsampling each at 48KHz, carried mostly very high-level information, not any audio specifics, so those I could keep without reintroducing artifacts. Introducing the 3rd last or earlier starts to severely hurt model performance.
I’m Absolutely Right!
Now, I’ve got a DEMUCS-style model with only the two deepest encoder-decoder skip connections, supplying just enough information for the model to know what each is, without any actual fine detail being communicated. Copying the Descript Audio Codec recipe, I’m using Snake activation function, weight normalization, and MPD + MS-STFT-D, with multi-scale mel loss. My U-Net has 28M total parameters.
This took roughly 3 days of training on a single AMD Instinct MI300X, provided by Hot Aisle, with PyTorch/ROCm. The dataset is ~20 hours of degraded-original audio pairs
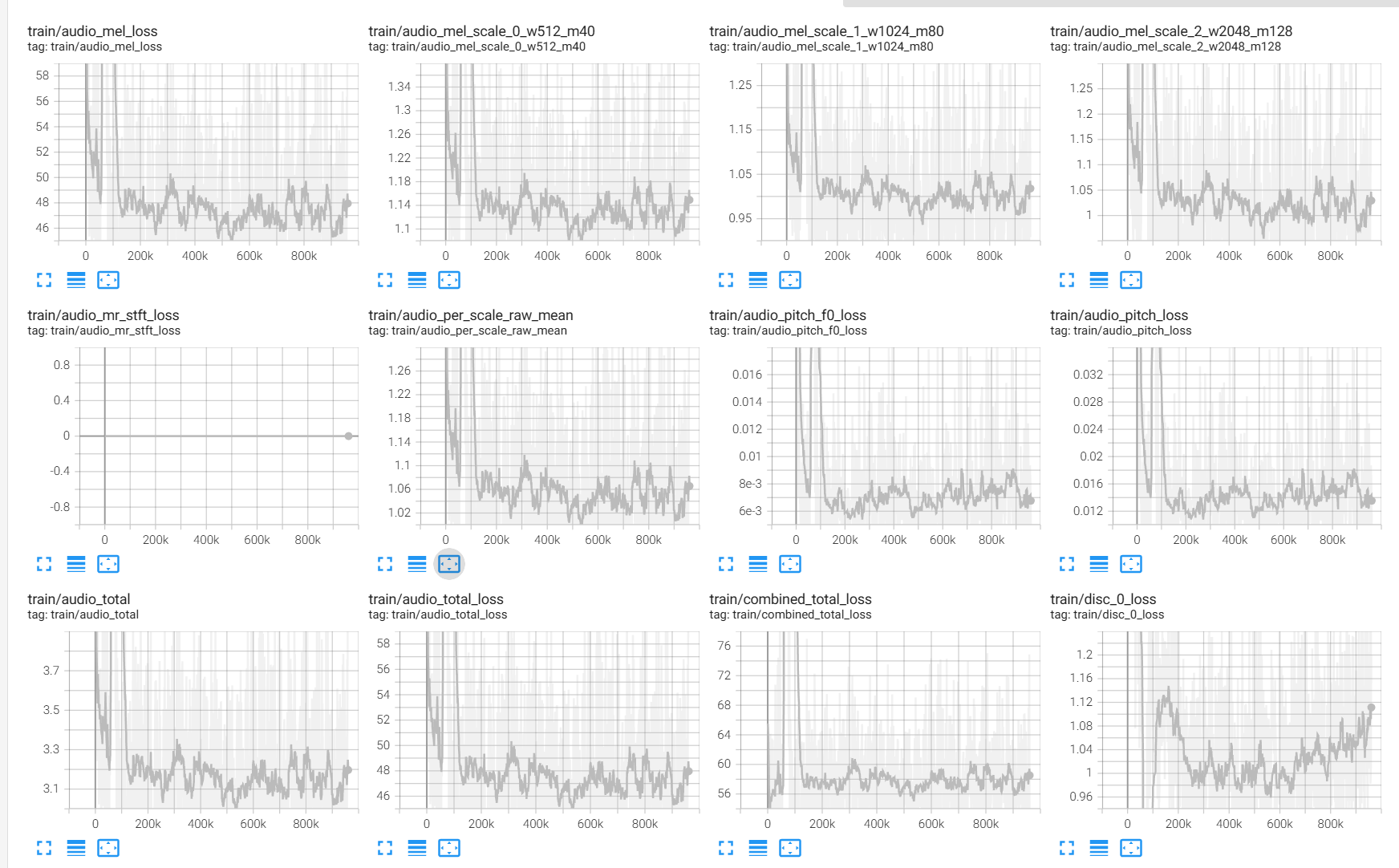
And with that, the model actually trained, because the decoder could no longer cheat by copying what the skip connections said: this generator had to invent structure, because it knew very little.
Here is one audio sample. This dataset is semi-private, so I cannot share much.
Degraded: (after NeuCodec, 24KHz):
Repaired and upsampled:
Modified MS-STFT Discriminator
The MS-STFT discriminator, not introduced by Descript Audio Codec, but used there, works by taking STFT of input audio at multiple resolutions and telling the difference between each. The default one takes in 2 channels per spectrogram: complex and real, of the STFT, raw.
I modified mine so that it takes 3 channels: log1p magnitude, sin and cos of phase.
The objective of this is to make the representation as informative and clear as possible. For phase, I use sin and cos because encoding it like that is friendlier than raw phase, which is a messy angle. As for magnitude, at first, I used log-magnitude (with an epsilon to prevent log 0), but remembered that I liked log1p as a transformation, so I plotted STFT with log1p vs log-mag


As you can see, log1p magnitude is much more informative than raw log-magnitude: low and high energy spots are clearly differentiated, while in log space, they all blur together. Indeed, the moment I switched the discriminator to log1p for magnitude, I saw a clear performance uplift, and the generator had a much easier time keeping up with the discriminator, its gradients were better, leading to the D pointing out more real flaws in the audio than wasting capacity on pointing out irrelevant differences in low-energy bins.
Trying to use raw magnitude and phase in the D resulted in the model eating shit 5k steps into adversarial training, with the audio samples sounding like an angry diesel engine; trying to use it in its original form (discriminate complex STFT raw) resulted in NaN loss. Therefore, I’ll stick to my STFT discriminator in this configuration.
Lastly, at the suggestion of Claude Opus 4.5 (Anthropic really put something special in this model), I added a phase gate: phase is masked out when the energy is too low, so the discriminator doesn’t waste capacity on silence.
Representation matters. Be nice to the gradient, and it will reward you.
Conclusion
So yeah, now we’ve learned the importance of knowing what a system does and what its parts are for: when the U-Net fights against you, make it less U-Net-y!
Now, I have every piece of my TTS pipeline: the TTS model itself (Echolancer), neural audio codec (NeuCodec — not mine), and audio upsampler (this model). I plan on training it on a more general dataset and releasing this thing soon
And thanks to Hot Aisle and AI at AMD for compute sugar daddying my unhinged experiments. I experimented and built a TTS stack entirely on AMD hardware.