

In my previous post, I introduced ReLUGT, APTxS1-T and ReLUGTz in a tiny classification run. Go read it if you haven’t already.
Now, it’s time to scale up a little.

The Run
I decided to set up a half-size GPT-2 model, helped by o1-mini and some GPT2 from scratch repo I found. The dataset is TinyStories GPT4 V2
Ignore the red around the Context length, that’s MathJax
The batch size is 14 because ReLUGTz would give CUDA OOM with 16, and to equalize the playing field it was set for the other functions even though they could fit 16. Model has about 82M parameters.
Only one run per activation function this time, where I chose:
SwiGLU: The GLU variant Llama and everyone uses, SiLU w/gating
GeGLU: Used by Google’s Gemma, GeLU w/gating.
ReLUGTz: The one I’m proposing. ReLUGT w/gating
I turned evaluation off because the training would freeze with 100% GPU usage if the model went into eval, so only training loss for this one. I could fix it, but I am too lazy to. Come on, give me a break
All models were trained on a single RTX 4090 with mixed precision, bfloat16. Each run took almost 8 hours to complete.
Observations
Stepwise, ReLUGTz reduces faster than the other loss functions:

Zooming in:

Now, ReLUGTz is 8.5% slower than the other GLU variants (and uses a bit more VRAM), with the forward pass wrapped in torch.jit.script, which gives it a 5x speed boost. Why? I don’t know.
However, even if we make the X axis time, we can still observe an advantage:

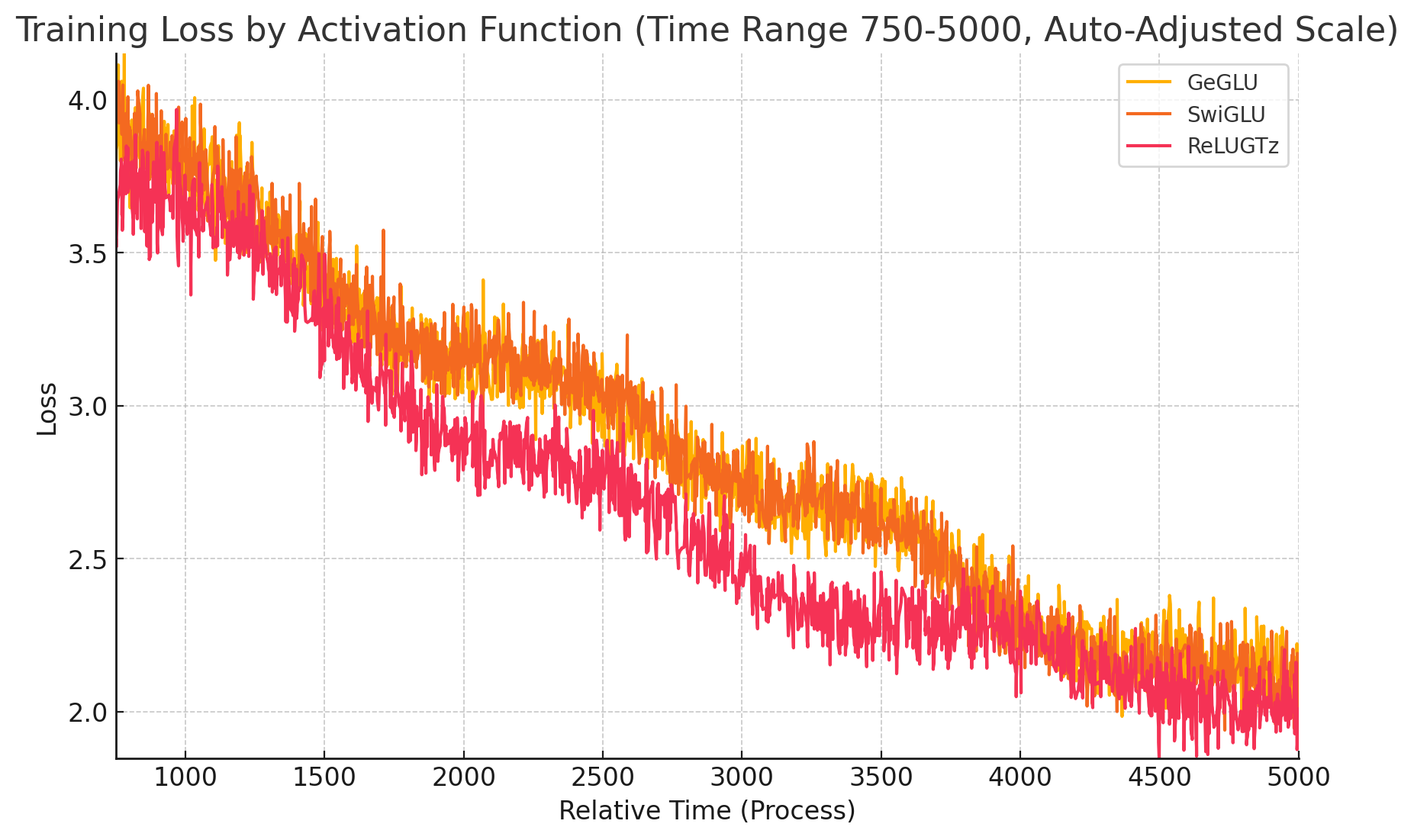
So, despite the slowdown, ReLUGTz is objectively faster than the conventional GLU variants.
Thank God (aka. Sam Altman) for ChatGPT’s advanced data analysis mode. Just throw CSVs in and ask it for stuff.
While it is faster to converge, it ends up with a slightly higher loss at the very end. Here I had my handy assistant split it into 10 “sectors” to observe the trend.
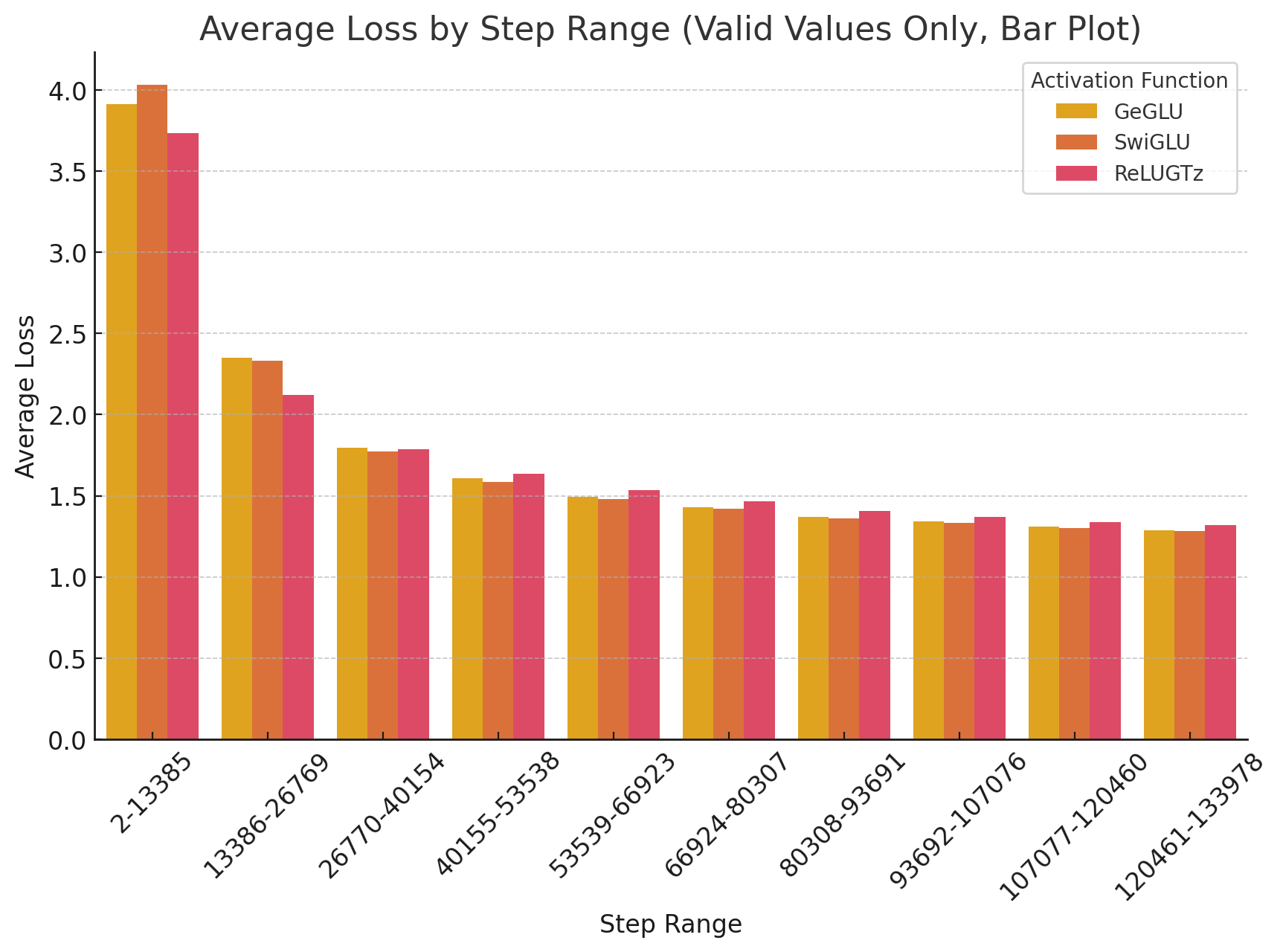
I argue that this higher loss thing is irrelevant, as this is a clumsy run on five epochs on TinyStories, it’s probably overfit to hell beyond the second or third epoch. The learning rate scheduler is set for 3000 epochs, so it didn’t decay either; the model reduces most of its loss by a little less than 30k steps, and that’s what matters. In a real-world scenario, you’d adjust the hparams to squeeze as much juice out of this as possible.
More specifically, ReLUGTz stopped being the lowest loss at around 28.5k steps. I asked my assistant to split into 5 sectors before and after

Before, GTz was handily beating both, but then SwiGLU started catching up to it, and surpassed it, maintaining a small gap.
My theory is that ReLUGTz is more sensitive to overtraining because of the parametric nature. Now, loss isn’t everything, inference performance matters, and I’ve done some tests on my FastSpeech2-based model, and I can tell you the speech is better.
There’s not much inference performance that can be compared when the generated stories are like this:
One day, a little girl named Lily was playing with her toy car. She loved her red car very much. But today, the car was broken. Lily was very sad and could not play with her red car.
Lily's mom saw her sad face and asked, "Why are you sad?" Lily showed her the broken car and said, "My red car is broken." Her mom smiled and said, "Don't worry, we can fix it."
So, they both tried to fix the car. They had fun, but it did not work. Lily's dog, Max, came in and saw Lily was sad. He decided to help them complete all. Max picked up the broken blue car in his mouth and brought it back to them.
Lily was very happy and said, "Thank you, Max!" They all played together with the fixed toy car. And they lived happily ever after.
Oh, talking about parametric nature:

This is a plot of the final learned activations after 5 epochs on TinyStories. As you can see, my theory is valid: different layer specializations lead to autograd optimizing the curves differently.
I mentioned higher VRAM usage, so here is a visualization:

I don’t consider this to be a big issue. If gradient accumulation didn’t exist, I’d be concerned — but alas, it does exist, so I’m not.
Conclusion
Here, I’ve scaled up ReLUGTz and proven, in a simple run, that it can reduce loss faster, and learn to further specialize layers when done with a very small GPT-2 style model, at the cost of slightly higher VRAM usage and slower per-step time. More scaling remains to be done however, but this is a step in the right direction.