

Introduction: Why Flash Attention?
If you’re reading this, I assume you know a thing a two about transformers already, so let’s make this quick.
Transformers, introduced in Attention Is All You Need by Vaswani et al, revolutionized AI with its multi head attention mechanism, which can attend to many spots across the whole sequence simultaneously; however, this power came at a cost.
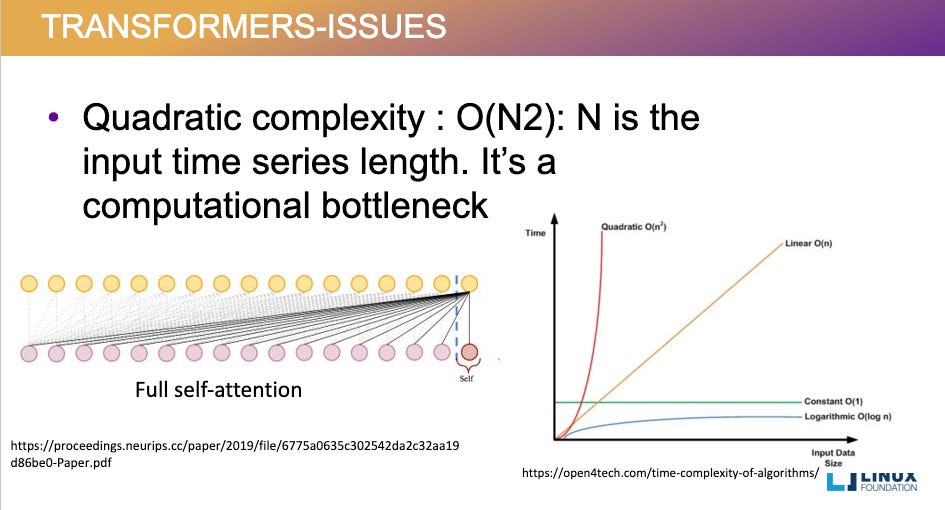
The standard scaled dot product attention has quadratic time and memory complexity in the sequence length. In simple terms, if you double the length of an input sequence, the computation takes four times as long and uses four times as much memory. This becomes a major bottleneck for long sequences like lengthy documents or high-res images. Researchers tried clever tricks (sparse or low-rank attention) to tame this growth, but those often sacrificed accuracy for limited real speedups.
In 2022, Tri Dao and friends introduced Flash Attention, where, instead of the naive approach that writes a gigantic attention score matrix to GPU memory, they proposed an IO-aware strategy: it restructures the computation to minimize memory reads/writes and keep data on-chip (in fast SRAM cache) as much as possible, primarily by tiling the attention computation and fusing several operations
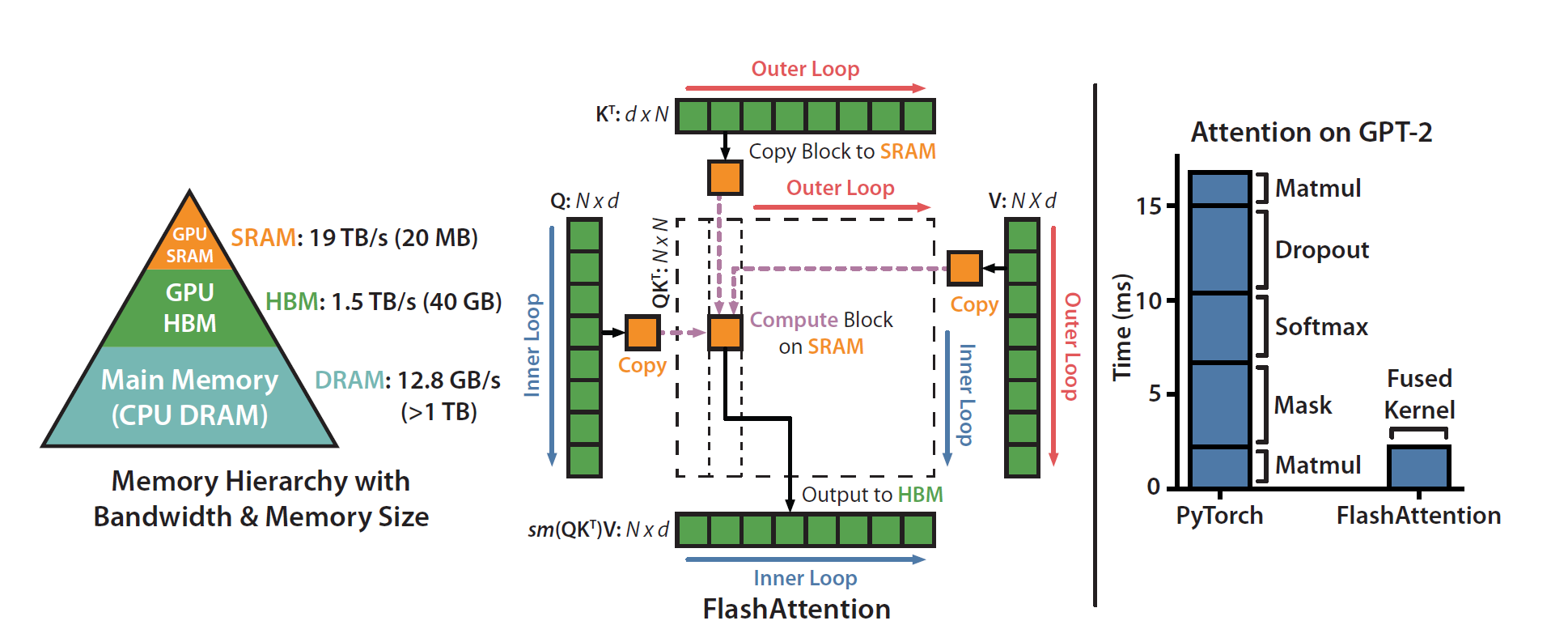
Thanks to the aforementioned optimizations, FlashAttention achieves a 2-4x speedup and 10-20x less memory usage compared to the standard approach, most importantly without any approximations: the results are identical to normal attention.
This didn’t only cut down on training time but also enabled Transformers to handle previously unfeasible sequence lengths: models trained with FlashAttention could successfully learn from sequences of 16k or even 64k tokens. For example, a long-range benchmark called Path-X (which has a 16k-token input) had stumped standard Transformers (they only achieved random-chance accuracy). With FlashAttention allowing a longer context, a Transformer was for the first time able to beat random chance on Path-X.
Once again, all this back in 2022. Nowadays, we have LLMs with 1M context length. All thanks partially FlashAttention and its successors, FlashAttention 2 (released 2023) and 3 (~2024, optimized for NVIDIA Hopper), with the second iteration bringing in a 2x speedup over its predecessor. This is just a primer so we won’t go into detail.
Integration
Since its benefits were too big to ignore and it was open source, Flash Attention was quickly adopted across the ML ecosystem; for example, PyTorch, the most widely used deep learning library, brought native support for FlashAttention 2 as of PyTorch 2.2: the torch.nn.functional.scaled_dot_product_attention function will automatically use FlashAttention under the hood when possible on NVIDIA GPUs. In PyTorch 2.3, said feature was extended on its ROCm backend, bringing fast native attention to AMD hardware.
At first, Flash Attention came out as a CUDA kernel, making it NVIDIA-exclusive, but quickly found its way into the ROCm ecosystem. Today, on an AMD Instinct MI300X, we have five options to choose from:
ROCm/Flash Attention 2, Composable Kernel (CK) and Triton backends. We’ll focus on the Triton one as it is feature complete and even has an FP8 variant.
PyTorch
scaled_dot_product_attentionFlexAttention (since Torch 2.6.0)
So, naturally, I’ve asked myself: which one is the best? We’re about to find out.
Experiment
For this, I’m going to jump straight into a real-world benchmark: training karpathy’s nanoGPT, for 1000 iterations, on a single AMD Instinct MI300X, courtesy of Hot Aisle. The batch size will be 64 and block size 1024, to roughly more-than-half saturate the MI300X’s 192GB of VRAM with some very comfortable headroom for inefficiencies; between each run, everything is identical except for how scaled dot product attention is calculated.
Also, by default, the repo does torch.compile on the entire model. This will be turned off here. We’ll be testing 7 (yes, seven) variants:
Flash Attention 2 Triton: ROCm/Flash Attention 2 setup with
FLASH_ATTENTION_TRITON_AMD_ENABLE="TRUE"Flash Attention 2 Triton (Autotune): Same as above, but training script run with
FLASH_ATTENTION_TRITON_AMD_AUTOTUNE="TRUE"Flash Attention 2 Triton (FP8)12: Like the 1st, but using the FP8 version (
flash_attn_qkvpacked_fp8_func)Flex Attention: PyTorch 2.6.0’s
torch.nn.attention.flex_attention, wrapped intorch.compilewithdynamic=Falsebecause it has to be compiled to work.Transformer Engine Triton: Using ROCm/TransformerEngine’s
te.DotProductAttentionwithNVTE_FUSED_ATTN_AOTRITON=1on runtimeNaive Attention: For a baseline, attention calculated the old-fashioned way with manual Torch code, no specialized kernels
Torch SDPA: PyTorch
scaled_dot_product_attention, likely using a CK backend.
I had o3 write me the modified classes, and looked each of them over for anything wrong.
Results
First off, which I think is the most important, none of the kernels differed in any relevant way in loss values, except for Transformer Engine’s, which increases it (dark blue line)
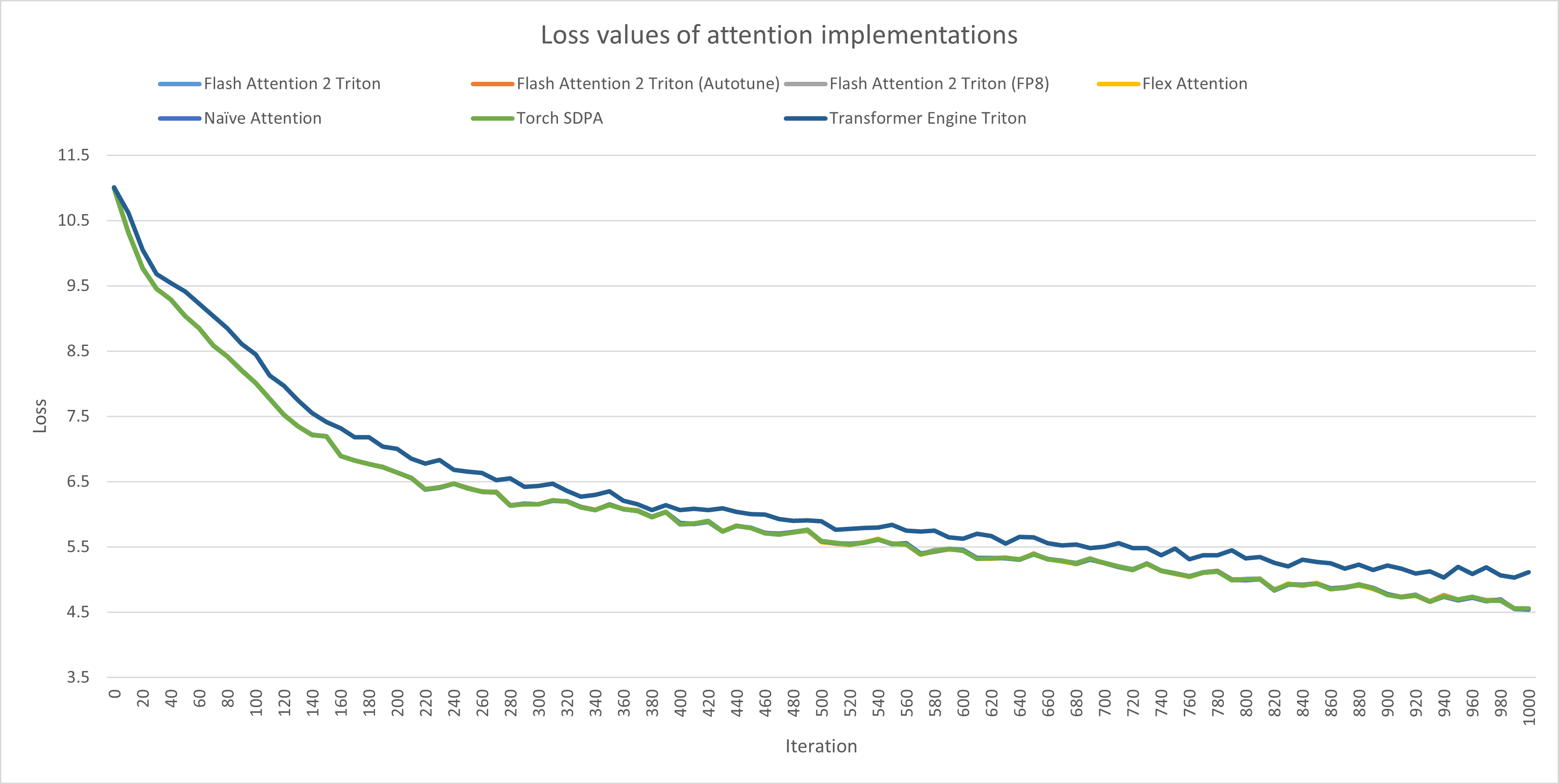
This immediately makes Transformer Engine’s attention kernel unusable, at least in my experience.
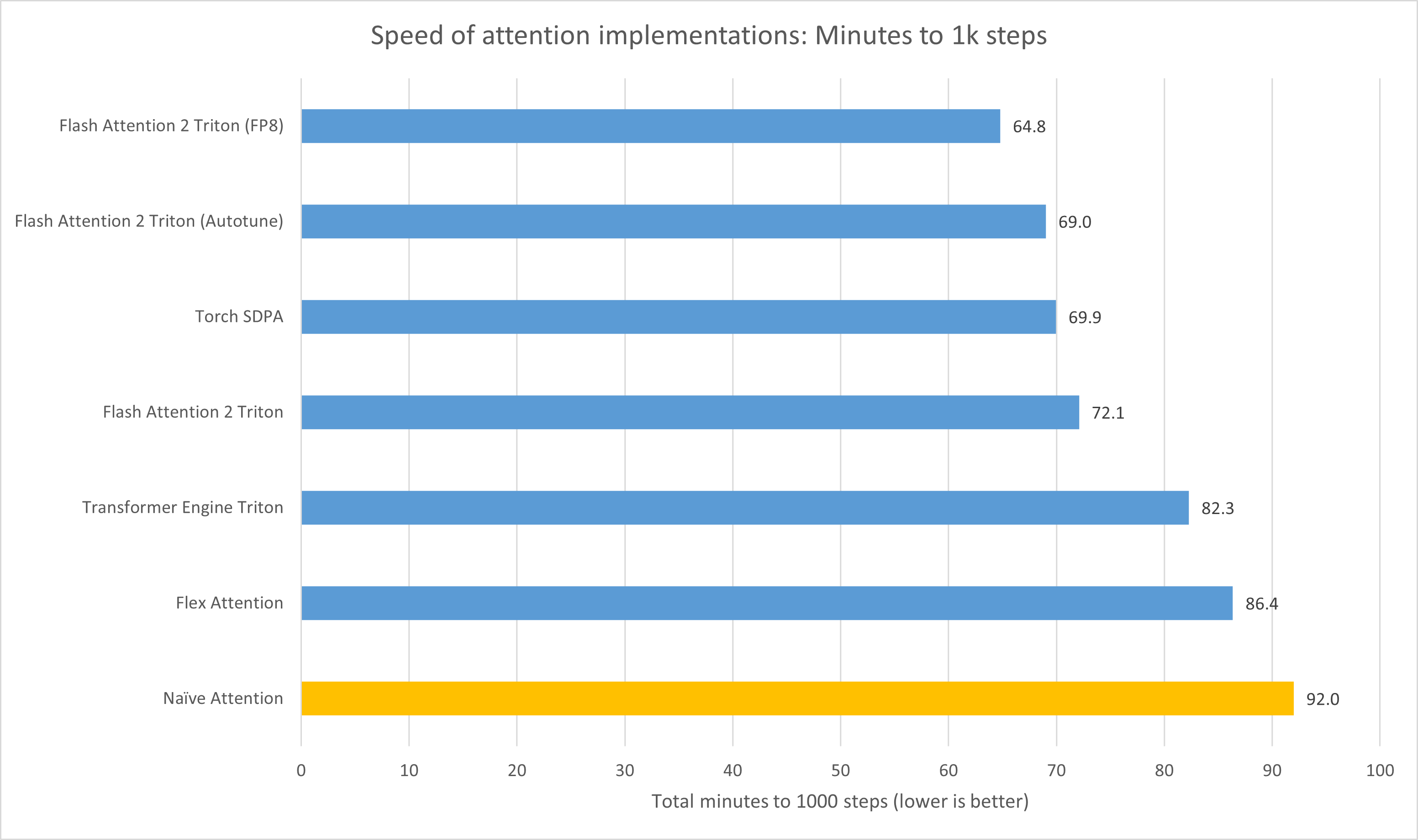
Now, let’s tackle the speed tests: as I’ve said before, all runs are for 1000 steps. Naive attention, for your visual aid, is in yellow.
Now let’s look at the speeds from a relative to naive perspective
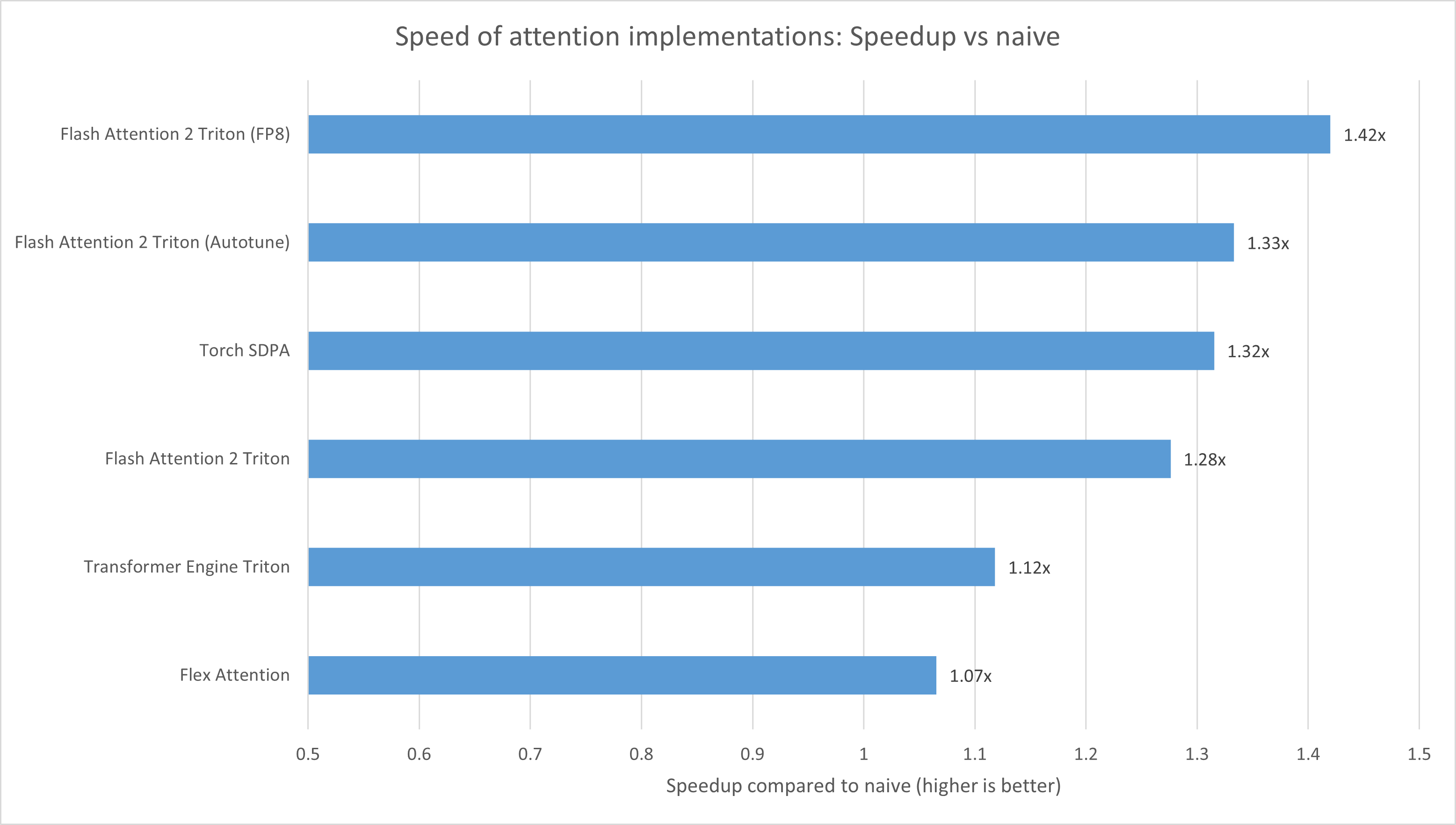
As you can see, the fastest is Flash Attention 2 Triton with FP8, with Torch SDPA slightly beating Flash Attention 2 Triton without autotune, but being beaten with, and Transformer Engine Triton providing only a small speedup (which is more than canceled out by the increase in loss), and Flex giving an even tinier one (but at least it’s real since it doesn’t change the loss)
But before going into memory, I’d like to clarify a little thing. Earlier I cited that FlashAttention provides a 2-4x speedup, but we’re not quite seeing that here: the reason is because I’m measuring this in whole model training run time, that is, Attention + LayerNorm + activations + optimizer, etc etc… for most models, attention tends to take up ~30% of compute time.
With that out of the way, let’s look at memory savings, another big benefit of Flash Attention, crucial for long context.
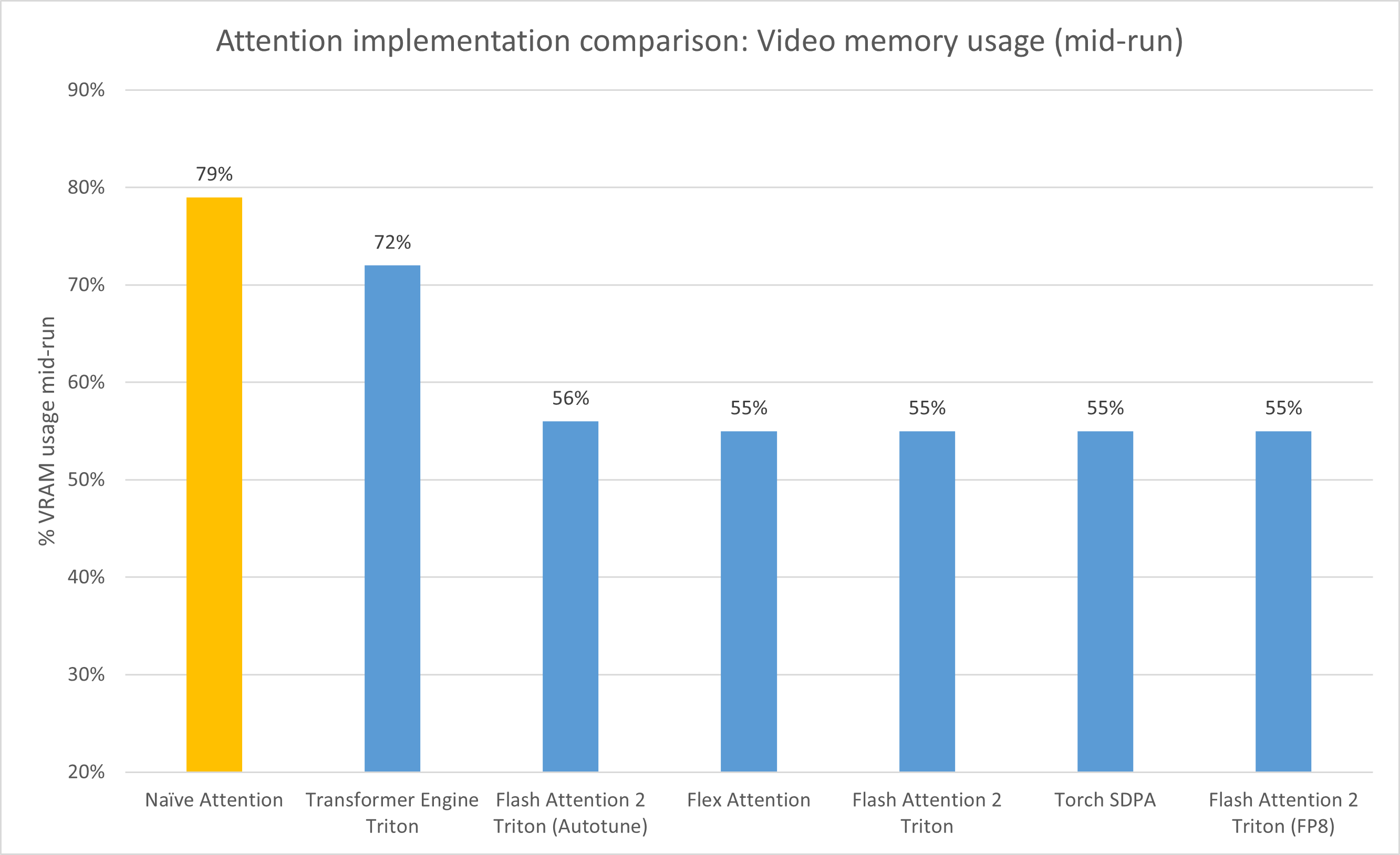
As expected, the naive approach takes up the most, followed by the anemic Transformer Engine, then the rest are roughly equal, with modest 24% VRAM savings at just 64 batch size and 1024 block size, I’m sure it’d be more pronounced at longer contexts.
Thankfully, Weights and Biases also logs GPU memory activity, so we can see what’s going on:
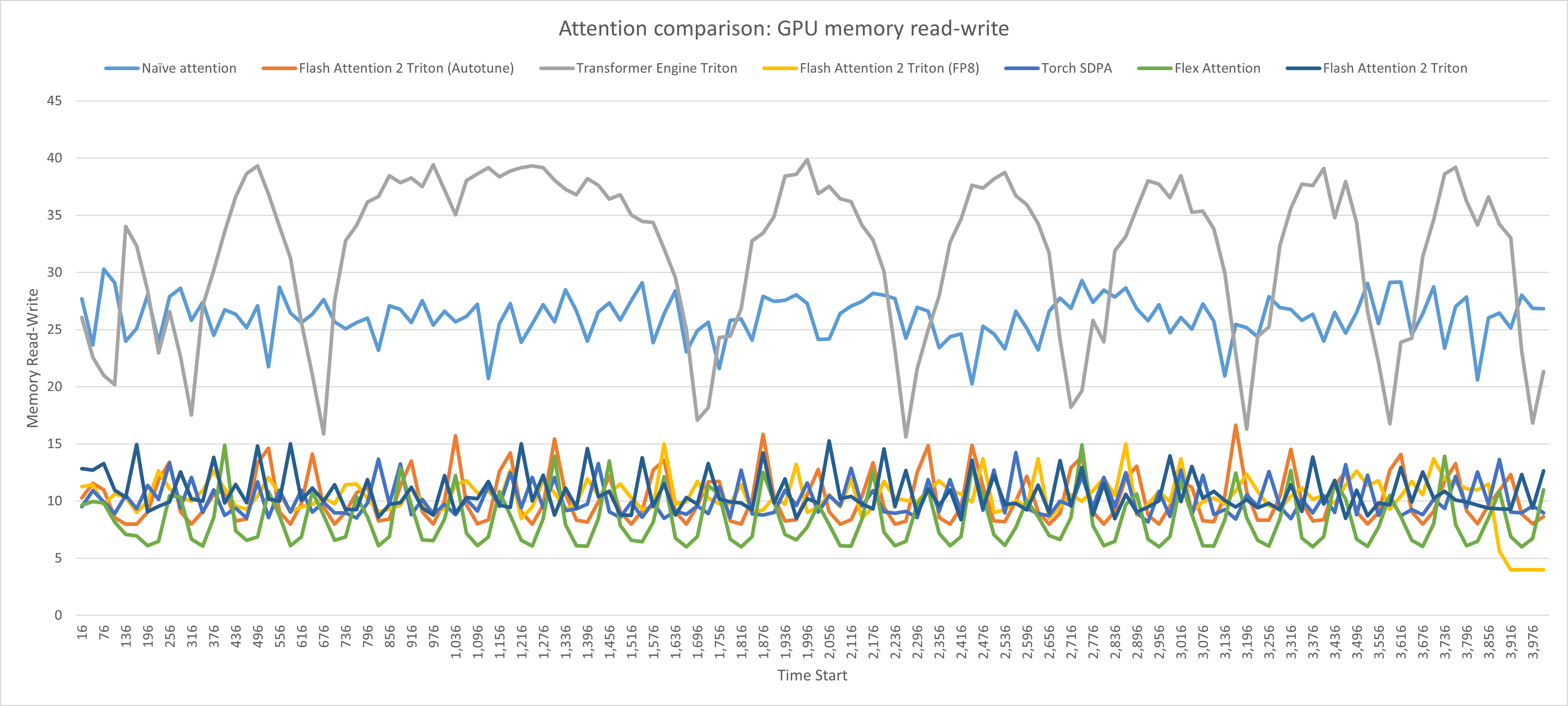
As you can see, one thing the bad attention variants have in common is that they waste a lot of time in HBM, unlike the efficient ones.
Conclusion
So, here’s how I’d rank efficient attention kernels in ROCm, taking into account not only performance, but ease of installation and feature completeness
✅ ✅ ✅ Flash Attention 2 Triton FP8: Setting it up was not only easy, but also supports a quite a few things, including arbitrary sizes, GQA, and my favorite, ALiBi, and it’s the fastest. I was going to deduct a point for poor documentation, but AMD solved my issue quick
✅ ✅ ✅ Flash Attention 2 Triton and Autotune: A bit less performant than FP8, but works
✅ ✅ Torch SDPA: Integrated into PyTorch, works well and good speedup, though I don’t think it supports ALiBi?
❌ Flex Attention: Tiny gain in speed, not even worth coding and dealing with making block masks. Maybe it’ll be more pronounced at scale? This is just 124M params on 1 GPU.
❌ Transformer Engine Triton: Very small gain in speed at a hit to loss.
So, yeah, what else can I add? That’s my dive into efficient attention kernels in AMD ROcm.
CHANGELOG:
25/07/2025 00:31: Fixed incorrect use of Flex Attention making it slower than naive, had to wrap it in torch.compile.
Disclaimer: I’m a ROCm star, but I am not perfect, and there is a chance some of the performance issues could’ve been an oversight on my part. However, I did check to the best of my ability that I was using everything properly.
Trying to combine autotune and FP8 resulted in this error: /var/lib/jenkins/triton/third_party/amd/lib/TritonAMDGPUTransforms/AccelerateAMDMatmul.cpp:151: llvm::FailureOr<mlir::MfmaInsn> {anonymous}::chooseMfmaInstruction(mlir::RankedTensorType, mlir::Type, mlir::Type, int, int, int): Assertion `inputKSize % kDim == 0' failed.
The FP8 variant was effectively hidden away behind bad documentation, but kudos to AMD for stepping in real quick.